

How serious are IBM’s OpenPOWER efforts? It is a question we got a lot after publishing our reviews of the POWER8 and POWER8 servers. Despite the fact that IBM has launched several scale out servers, many people still do not see IBM as a challenger for Intel’s midrange Xeon E5 business. Those doubts are understandable if you consider that Linux based systems are only 10% of IBM’s Power systems sales. And some of those Linux based systems are high-end scale up servers. Although the available financial info gives us a very murky view, nobody doubts that the Linux based scale out servers are only a tiny part of IBM’s revenue. Hence the doubts whether IBM is really serious about the much less profitable midrange server market.
At the same time, IBM’s strongholds – mainframes, high-end servers and the associated lucrative software and consulting services – are in a slow but steady decline. Many years ago IBM put into motion plans to turn the ship around, by focusing on Cloud services (Softlayer& Bluemix), Watson (Cognitive applications, AI & Analytics) and … OpenPOWER. If you pay close attention to what the company has been saying there is little doubt: these three initiatives will make or break IBM’s future. And cloud services will be based upon scale out servers.

The story of Watson, the poster child of the new innovative IBM, is even more telling. Watson, probably the most advanced natural language processing software on the planet, started its career on typical IBM Big Iron: a cluster of 90 POWER 750 servers, containing 2880 Power7 CPUs and 16 TB of RAM. We were even surprised that this AI marvel was on the market for no more than 3 million dollars. The next generation for Watson cloud services will be (is?) based upon OpenPOWER hardware: a scale out dual POWER8 server with NVIDIA’s K80 GPU accelerator as the basic building block. An OpenPOWER based Watson service is simply much cheaper and faster, even in IBM’s own datacenters. But there is more to it than just IBM’s internal affairs.
Google seems to be quite enthusiastic about OpenPOWER. Google always experimented with different architectures, and told the world more than once that it was playing around with ARM and POWER based servers. However, the plans with OpenPOWER hardware are very tangible and require large investments: Google is actively developing a POWER9 server with Rackspace.

“Zaius, the OpenPOWER POWER9 server of Google and Rackspace”
Google has also publicly stated that “For most Googlers, enabling POWER is a config change”. This far transcends the typical “we experimenting with that stuff in the labs”.
So no wonder that IBM is giving this currently low revenue but very promising project such a high priority. And the pace increases: IBM just announced even more “OpenPOWER based” servers. The scale out server family is expanding quickly…
Those who suggested that IBM’s scale out servers were just a half-hearted effort that would quickly get strangled by the desire to protect the high margin big iron servers could not have been more wrong. IBM just launched 3 new servers, and all of them are affordable scale out servers. IBM is now very aggressively going after the market it has (almost) completely lost to Intel’s Xeon: HPC. At the same time IBM is emphasizing the determination to play an important role in the emerging “machine learning” and “Big Data” market.

The S822LC “Big Data” and S821LC use mature and proven – some would say “older” – technology: the “OpenPOWER version” of the POWER8 and NVIDIA’s Tesla K80. There are some interesting new facts to discuss though. First of all, these servers are made by Supermicro, confirming the close relation between the two companies and that OpenPOWER is indeed “Open”. Supermicro is the market leader in the HPC market, and the fact that Supermicro chose to invest in OpenPOWER is a promissing sign: IBM is on to something, it is not another “me too” effort.
Secondly, these servers use (registered) DDR4 RAM as opposed to DDR3 as found in servers like the S812LC and SL822. Since they are still communicating via the “Centaur” memory buffers, this will not give any tangible performance boost, but it means that the servers are making use of the most popular and thus cheapest server memory technology.
The 2U S822LC “Big Data” looks like a solid offering. Pricing starts at $ 5999 (one 3.3 GHz 8-core, 64 GB RAM, no GPU), but realistically a full equipped server (two 10-cores, one K80, 128 GB) is around $ 16000. If you do not need the GPU, a server with two 10-cores, 256 GB, 2x 10 GB and two 1 TB disks costs around $ 13341. The CPU inside is still the 190W TDP single chip 10-core (at 2.9-3.5 GHz boost) that we tested a while ago. There is also an 8-core (3.3 – 3.7 GHz boost) alternative.
The 1U S821LC starts at $ 5900. The 1U form factor limits the POWER8 to much lower power envelopes. The 8-core chip runs at 2.3 GHz (135W TDP), the 10-core is allowed to consume a greater 145W, but runs at a meager – for POWER8 standards – 2.1 GHz. We can imagine that this is indeed based upon the customer feedback of space constrained datacenters, as IBM claims. We feel however that it makes the S821LC server less attractive as one of the distinguishing features of the POWER8 is the high single threaded performance. The POWER8 was simply not designed to run inside a 1U server. On the other side of the coin, a 2.1 GHz 10-core might still be fast enough to feed the GPU with the necessary data in some HPC applications.
Digging a bit deeper, the shiny new S822LC is a different beast. If offers the “NVIDIA improved” POWER8. The core remained the same but the CPU now comes with NVIDIA’s NVlink technology. Four of these NVLink ports allows the S822LC to make a very fast (80 GB/s full duplex) and direct link with the latest and greatest of NVIDIA GPUs: the Tesla P100. Ryan has discussed NVLink and the 16 nm P100 in more detail a few months ago. I quote:
NVLink will allow GPUs to connect to either each other or to supporting CPUs (OpenPOWER), offering a higher bandwidth cache coherent link than what PCIe 3 offers. This link will be important for NVIDIA for a number of reasons, as their scalability and unified memory plans are built around its functionality.
Each P100 has a 720 GB/s of memory bandwidth, powered by 16 GB of HBM2 stacked memory. If you combine that with the fact that the P100 has more than twice the processing power in half precision and double precision floating point (important for machine learning algorithms) than its predecessor, it easy to understand why the data transfers from the CPU to GPU can easily become a bottleneck in some applications.
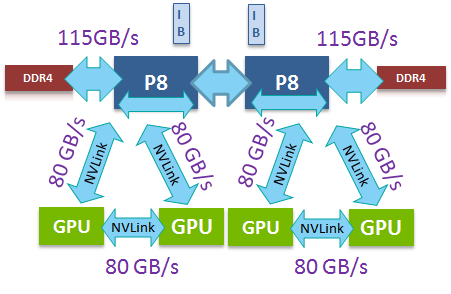
This means that the “OpenPOWER way of working” has enabled the IBM POWER8 to be the first platform to fully leverage the best of NVIDIA’s technology. It is almost certain that Intel will not add NVLink to their products, as Intel went a totally different route with the Xeon and Xeon Phi. NVLink offers 80 GB/s of full-duplex connectivity per GPU, which is provided in the form of 4 20GB/s connections that can be routed between GPUs and CPUs as needed. By comparison, a P100 that plugs into an x16 PCIe 3.0 slot only gets 16 GB/s full duplex to communicate with both the CPU and the other GPUs. So theoretically, a quad NVLink setup from GPU to CPU offers at least 2.5 times more bandwidth. However, IBM claims that in reality the advantage is 2.8x as the NVLink is more efficient than PCIe (83% of theoretical bandwidth vs. 74%).

The NVLink equipped P100 cards will make use of the SXM2 form factor and come with a bonus: they deliver 13% more raw compute performance than the “classic” PCIe card due to the higher TDP (300W vs 250W). By the numbers, this amounts to 5.3 TFLOPS double precision for the SXM2 version, versus 4.7 TFLOPS for the PCIe version.
We have to check for ourselves of course, but IBM claims that compared to a dual K80 setup, a dual P100 gets a 2.07x speedup on the S822LC HPC. The same dual P100 on a fast Xeon with PCIe 3.0 only saw a 1.5x speedup. The benchmark used was a rather exotic Lattice QCD, or an approach to “solve quantum chromodynamics”.
However, IBM reports that NVLink removes performance bottlenecks in
- FFT (signal processing)
- STAC-A2 (risk analysis)
- CPMD – computational chemistry
- Hash tables (used in many algorithms, security and big data)
- Spark
Those got our attention as, they are not some exotic niche HPC applications, but wide spread software components/frameworks used in both the HPC and data analytics world.
NVIDIA also claims that thanks to NVLink and the improved page migration engine capabilities, a new breed of GPU accelerated applications will be possible. The unified memory space (CUDA 6) introduced in Kepler was a huge step forward for the CUDA programmers: they no longer had to explicitly copy data from the CPU to the GPU. The Page Migration Engine would do that for them.
But the current system (Kepler and Maxwell) also had quite a few limitations. For example the memory space where the CPU and GPU are sharing data was limited to size of the GPU memory (typically 8-16 GB). The P100 now gets 49-bit virtual addressing, which means CUDA programs can thread every available RAM byte as one big virtual space. In the case of the newly launched S822LC, this means up to 1 TB of DRAM, and consequently 1 TB of memory space. Secondly, the whole virtual address space is coherent thanks to the new page fault mechanism: both the CPU and GPU can access the DRAM together. This requires OS support, and NVIDIA cooperated with the Linux community to make this happen.
Of course as the unified memory space gets larger, the amount of data to transfer back and forth gets larger too and that is where NVLink and the extra memory bandwidth of the POWER8 have a large advantage. Remember that even the POWER8 with only 4 buffer chips delivered twice as much memory bandwidth than the best Xeons. The higher end POWER8 have 8 buffer chips, and as a result offer almost twice as much memory bandwidth.
NVLink, together with the beefy memory subsystem of the POWER8, ensures that CUDA applications using such a unified 1TB memory space can actually work well.

The POWER8 – al heatsinks – looks less hot headed now that it has the companion of 4 Tesla P100 GPUs…
The S822LC will cost less than $ 50000, and it offers a lot of FLOPS per dollar if you ask us. First consider that a single Tesla P100 SXM2 costs around $ 9500. The S822LC integrates four of them, two 10-core POWER8s and 256 GB of RAM. More than 21 TFLOPS (FP64) connected by the latest and greatest interconnects in a 2U box: the S822LC HPC is going to turn some heads.
Last but not least, note that once you add two or more GPUs which consume 300W each, the biggest disadvantage of the POWER8 almost literally melts away. The fact that each POWER8 CPU may consume 45-100W more than the high performance Xeons seems all of a sudden relative and not such a deal breaker anymore. Especially in the HPC world, where performance is more important than Watts.
As promised in the first part of our series on evaluating the POWER8, we got busy benchmarking real server applications. The latest IBM servers were not available to us yet, but we can still show some interesting benchmarks as the S812LC has a 10-core POWER8 CPU running at 2.92 GHz (and boosting to 3.5 GHz).

This single chip POWER8 is the same processor that power the new “IBM S822LC for big data” and “S822LC for HPC”.
And although it is not the latest and greatest, the S812LC is still an interesting server. It is the most affordable IBM POWER8 server in a very long time and offers some unique features. 32 DIMMs allow you get up to 1TB of DRAM (32 x 32 GB) without the need for disproportionally expensive 64 GB DIMMs. Two rear disk expansion bays offer 2 bays for booting the server (in RAID-1 if you like) and make sure that the 12 front bays can be used for data only. The system supports 6 TB SATA disks or 960 GB SSDs (Samsung).

Two redundant Platinum-brand 1200W PSUs feed the server build for big data.
For this article, the only current-generation Intel Broadwell-EP processors we had in the lab were the Xeon E5-2699 v4 and Xeon E5-2650 v4. Comparing the IBM POWER8 with the former was not fair: the Xeon costs almost 3 times ($ 4115) more than the midrange POWER8 chip ($ 1500). The latter was not an option either with a TDP of 90W. There are no Intel chips with 190W TDP, so we had to compromise.
The most comparable CPU that was available to us was the Xeon E5-2690 v3. It is a higher end midrange Intel SKU (135W TDP) that came out around the same time as the POWER8. If the 190W TDP POWER8 cannot beat this 135W TDP chip, IBM’s micro architects have not done a very good job. Don’t let the 2.6 GHz label fool you: this Haswell Xeon can boost to 3.1 GHz when all cores are active and to 3.5 GHz in a single thread situation. So it does have 2 cores extra and similar clockspeeds.

However we can’t ignore the current-generation Broadwell-EP entirely. To get a better idea how the midrange POWER8 compares to the latest Xeons, we had to add another midrange Xeon E5 v4 SKU. So we only enabled 14 of the 22-cores of the Xeon E5-2699 v4. This gives us a chip that is somewhere between the Xeon E5-2660 v4 (14 cores at 2 GHz) and E5-2680 v4 (14 cores at 2.4 GHz). Well, at least on paper. The Xeon E5-2680 v4 runs most of the time at 2.9 GHz in heavily multi-threaded situations (+5 steps, all cores active), while our Xeon E5-2699 v4 with 14 cores runs at 2.8 GHz (+6 turbo steps). As the TDP of the latter is higher, the turbo clock will be used for a higher percentage of the time. Bottom line, our Xeon E5-2699 v4 with 14 cores is very similar to an E5-2680 v4 with a 145 W TDP. As the Xeon E5-2680 costs around $ 1745, it is in the right price range. From a price/performance point of perspective that is as fair as we can get it.
For those looking to get the best performance per watt: we’ll save you some time and tell you that it does not get any better than the Xeon E5-2600 v4 series. Intel really went all the way to make sure that the Broadwell EP Xeon is a power sipper. And although the performance step is small, the Xeon E5-2600 v4 consumes much less than a similar Xeon E5 v3 SKU, let alone a CPU with a 190W TDP (+ 60-80W memory buffers).
Our testing was conducted on Ubuntu Server 15.10 (kernel 4.2.0) with gcc compiler version 5.2.1. The reason why we did not update was that we only got everything working with that version.
Last but not least, we want to note how the performance graphs have been color-coded. Orange is for used for the review POWER8 CPU. The latest generation of the Intel Xeon (v4) gets dark blue, the previous one (v3) gets light blue. Older Xeon generations are colored with the default gray.
IBM S812LC (2U)
The IBM S812LC is based up on Tyan’s “Habanero” platform. The board inside the IBM server is thus designed by Tyan.
| CPU | One IBM POWER8 2.92 GHz (up to 3.5 GHz Turbo) |
| RAM | 256 GB (16x16GB) DDR3-1333 |
| Internal Disks | 2x Samsung 850Pro 960 GB |
| Motherboard | Tyan SP012 |
| PSU | Delta Electronics DSP-1200AB 1200W |
Intel’s Xeon E5 Server – S2600WT (2U Chassis)
| CPU | One Intel Xeon processor E5-2699 v4 (2.2 GHz, 22c, 55MB L3, 145W) One “simulated” Intel Xeon processor E5-2680 v4 (2.2 GHz, 14c, 35MB L3, 145W) One Intel Xeon processor E5-2699 v3 (2.3 GHz, 18c, 45MB L3, 145W) One Intel Xeon processor E5-2690 v3 (3.2 GHz, 8c, 20MB L3, 135W) |
| RAM | 128 GB (8x16GB) Kingston DDR4-2400 or 256 GB (8x 32GB) Hynix DDR4-2133 |
| Internal Disks | 2x Samsung 850Pro 960 GB |
| Motherboard | Intel Server Board Wildcat Pass |
| PSU | Delta Electronics 750W DPS-750XB A (80+ Platinum) |
All C-states are enabled in the BIOS.
SuperMicro 6027R-73DARF (2U Chassis)
| CPU | Two Intel Xeon processor E5-2697 v2 (2.7GHz, 12c, 30MB L3, 130W) |
| RAM | 128GB (8x16GB) Samsung at 1866 MHz |
| Internal Disks | 2x Intel SSD3500 400GB |
| Motherboard | SuperMicro X9DRD-7LN4F |
| PSU | Supermicro 740W PWS-741P-1R (80+ Platinum) |
All C-states are enabled in the BIOS.
Other Notes
Both servers are fed by a standard European 230V (16 Amps max.) power line. The room temperature is monitored and kept at 23°C by our Airwell CRACs.
The SPECjbb 2015 benchmark has “a usage model based on a world-wide supermarket company with an IT infrastructure that handles a mix of point-of-sale requests, online purchases, and data-mining operations.” It uses the latest Java 7 features and makes use of XML, compressed communication, and messaging with security.
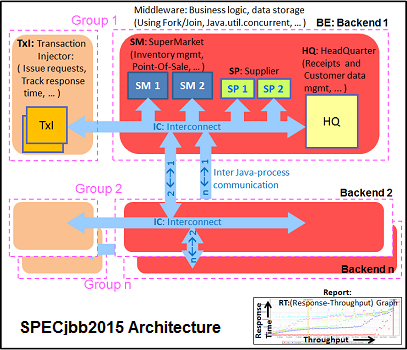
We tested with four groups of transaction injectors and backends. The reason why we use the “Multi JVM” test is that it is more realistic: multiple VMs on a server is a very common practice.
The Java version was OpenJDK 1.8.0_91. We applied relatively basic tuning to mimic real-world use, while aiming to fit everything inside a server with 128 GB of RAM:
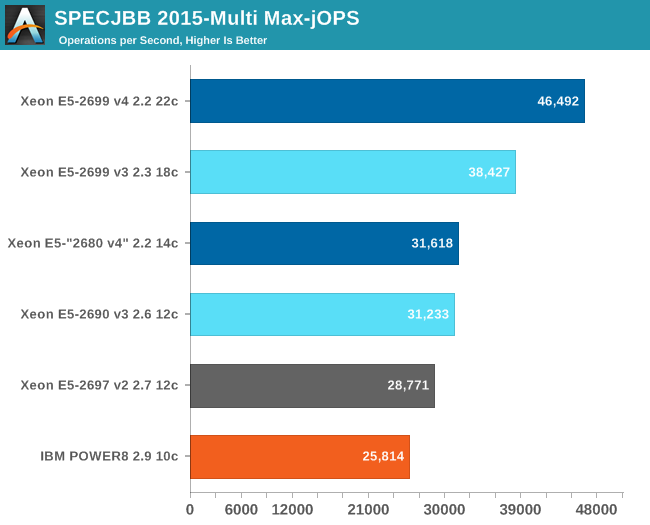
The graph below shows the maximum throughput numbers for our MultiJVM SPECJbb test.
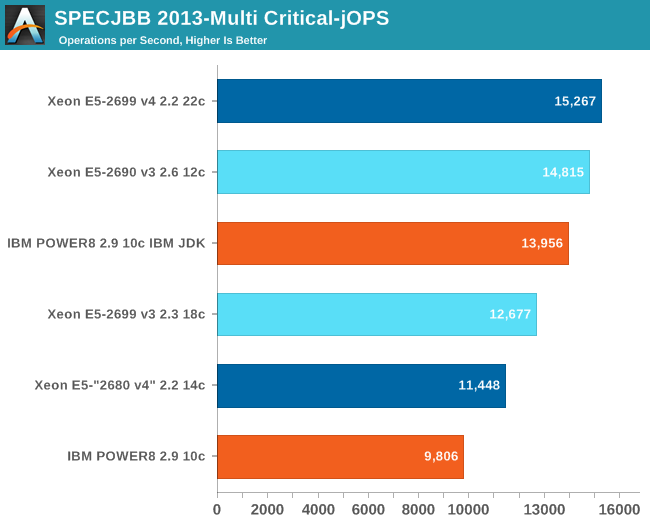
The Critical-jOPS metric is a throughput metric under response time constraint.
After checking the other benchmarks and IBM’s published benchmarks at spec.org we suspected that there was something suboptimal for the POWER8 server. A Java expert at IBM responded:
Currently OpenJDK 8 performance on power lags behind the IBM JDK for this benchmark, and is not reflective of the hardware. The gap is being closed by driving changes into OpenJDK 9 that will be back ported to OpenJDK 8.
So this is one of those cases where the “standard” open source ecosystem is not optimal. So we tried out IBM’s 64 bit SDK version LE 8.0-3.11. Out of the box, throughput got even worse. Only when we used more complicated tuning and more memory…
…did both critical and max-ops got better. We also had to use static huge pages (16 MB each) instead of transparent huge pages. We gave the Intel Xeons also 32 GB per VM and eight 32 GB DIMMs, but we did not use the IBM JDK as it caused a performance decrease.
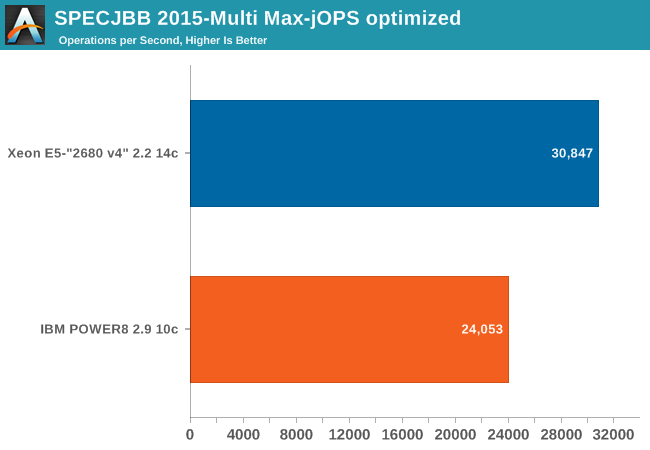
Both the Xeon and the IBM POWER8 max throughput got worse. In the case of Intel we can easily explain this: its 32 GB of DDR4-2133 memory offers less bandwidth and higher latency. In case of IBM, we can only say we lack knowledge of the IBM JDK.
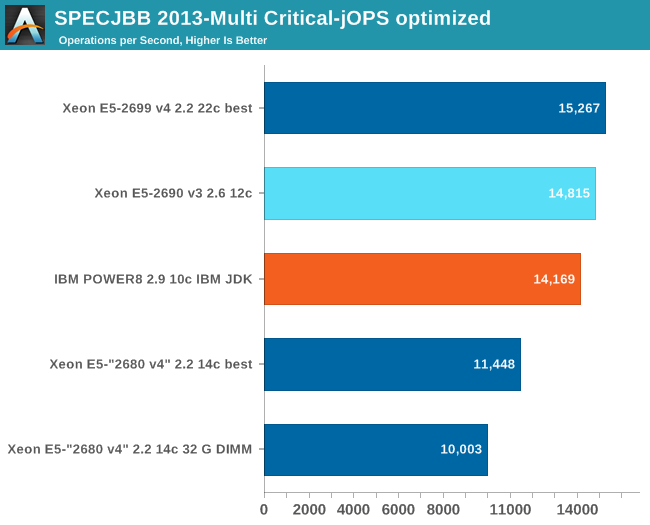
Again, the Xeon E5-2680 v4 loses performance due to the fact that we had to use memory.
This is not an apples to apples comparison as we would like it, but it gives a good indication that the IBM POWER8 might actually able to beat even more expensive Xeon E5s than our (simulated) Xeon E5-2680v4 with optimized software. A Xeon E5-2690 v4 ($ 2090) would be beaten by a decent margin and even the 2695v4 ($ 2400) might be in reach.
Thanks to the excellent repository of Percona, we were able to vastly improve our MySQL benchmarking with Sysbench. You cannot compare these results to the results published prior to the Cavium Thunder-X review: we made quite a few changes in the way we benchmark. We first upgraded the standard MySQL installation to the better performing Percona Server 5.7.
Secondly, we used Sysbench 0.5 (instead of 0.4) and we implemented the (lua) scripts that allow us to use multiple tables (8 in our case) instead of the default one. This makes the Sysbench benchmark much more realistic as running with one table creates a very artificial bottleneck.
For our testing we used the read-only OLTP benchmark, which is slightly less realistic, but still much more interesting than most other Sysbench tests. This allows us to measure CPU performance without creating an I/O bottleneck.
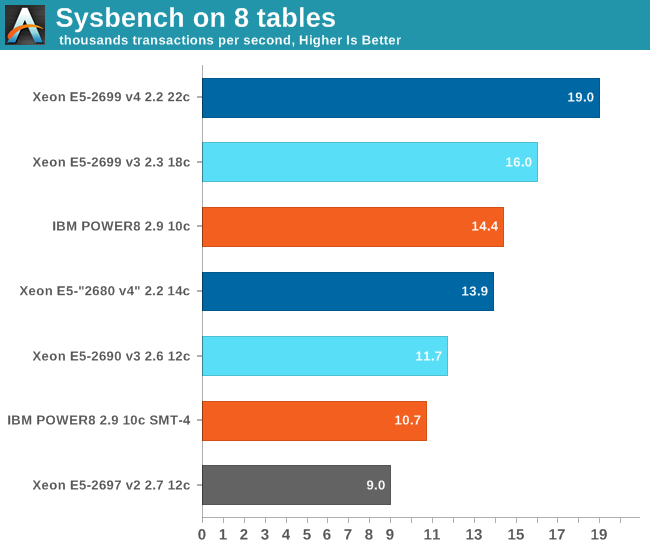
It is important to note that IBM has invested a lot of time in Postgres and MariaDB optimization. So our choice for MySQL is definitely not the most favorable. However, this is database we know best, and it will take some time before we fully master Postgres benchmarking. We already started with MariaDB testing, but the results were very similar. The reason is that we are probably missing some key optimizations.
Still, the IBM POWER8 does very well here, outperforming our simulated Xeon E5-2680 v4 by a small margin and thus keeping up with more expensive Xeons. Next we measure the 95th percentile response time, a response time which is statistically relevant for the users.
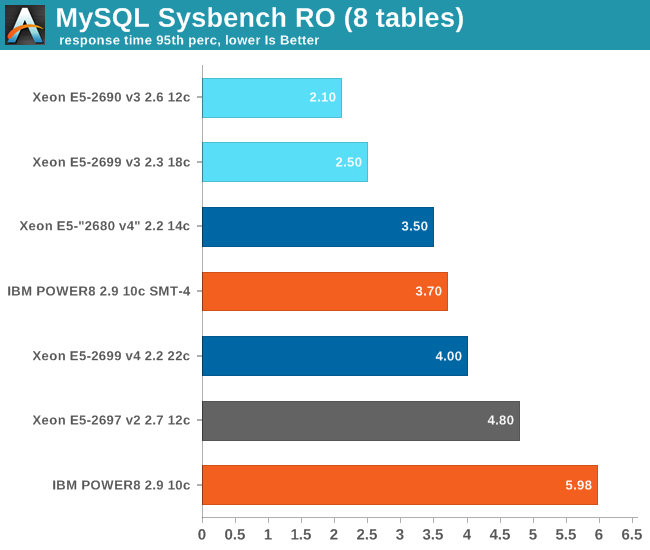
You do pay a price for the fact that 8 threads are running on one core. SMT-8 optimizes throughput at the cost of the response time of individual threads. Response times are quite a bit higher on the POWER8 than they are on the Intel Xeons. Only POWER specific optimization that makes better use of SMT-8 can remedy this.
Spark is wonderful framework, but you need some decent input data and some good coding skills to really test it. Speeding up Big Data applications is the top priority project at the lab I work for (Sizing Servers Lab of the University College of West-Flanders), so I was able to turn to the coding skills of Wannes De Smet to produce a benchmark that uses many of the Spark features and is based upon real world usage.

The test is described in the graph above. We first start with 300 GB of compressed data gathered from the CommonCrawl. These compressed files are a large amount of web archives. We decompress the data on the fly to avoid a long wait that is mostly storage related. We then extract the meaningful text data out of the archives by using the Java library “BoilerPipe”. Using the Stanford CoreNLP Natural Language Processing Toolkit, we extract entities (“words that mean something”) out of the text, and then count which URLs have the highest occurrence of these entities. The Alternating Least Square algorithm is then used to recommend which URLs are the most interesting for a certain subject.
We tested with Apache Spark 1.5 in standalone mode (non-clustered) as it took us a long time to make sure that the results were repetitive. For now, we keep version 1.5 to be able to compare with earlier results.
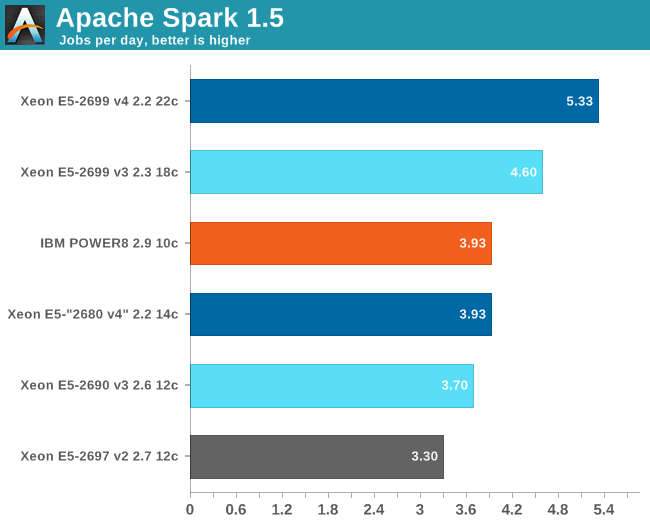
The POWER8 surprises here with excellent performance: it is able to keep with a 14 core Xeon E5 “Broadwell EP” and beats the midrange Xeon E5-2690 v3 by healthy margin. Remember, this is a midrange POWER8: there are SKUs that reach 3.4-3.8 GHz.
A large part of the server market is very sensitive to performance-per-watt. That includes the cloud vendors/hosts. For a smaller part of the market, top performance is more important than the performance/watt ratio. Indeed, for financial trading, big data analyses, large databases, and most HPC servers, total performance is the top priority. Energy consumption should not be outrageous, but it is not the most important concern.
We tested the energy consumption of our servers for a one-minute period in several situations. The first one is the point where the tested server performs best in MySQL: the highest throughput just before the response time goes up significantly. Then we look at the point where throughput is the highest (no matter what response time). This is the situation where the CPU is fully loaded.
| SKU | TDP (on paper) spec |
Idle Server W |
MySQL Best Throughput at Lowest Resp. Time (W) |
MySQL Max Throughput (W) |
Transaction /s |
Tr/watt |
| IBM POWER8 S812LC | 190 W | 221 | 259 | 260 | 14482 | 55 |
| Xeon E5-2699 v4 | 145 W | 67 | 213 | 235 | 18997 | 89 |
| Xeon E5-2690 v3 | 135 W | 84 | 249 | 254 | 11741 | 47 |
Throughput and single threaded performance were the priorities for designing POWER8. Power consumption stood probably much lower on the list, way behind RAS. The idle power shows us that you should not use the POWER8 in applications that run at low load for long periods.
Intel’s “Broadwell-EP” (Xeon E5 v4), by comparison, is the clear victor when it comes to performance per watt, and even without looking at Intel’s background, it’s clear from the data alone that more thought was put into that aspect.
However, considering that the POWER8 was launched around the same time as Intel Haswell, IBM’s multicore delivers a lot of integer performance per watt of energy it consumes. In fact, despite the power gobbling Centaur chips, despite the fact that MySQL is not the most POWER8 optimized application, IBM’s medium range POWER8 is capable of defeating Intel’s Haswell. While this is less relevant to the server buyer today, it does show that IBM’s engineering capabilities are competitive with Intel, which is good news for the upcoming POWER9 chip. The POWER9 chip will be the first POWER chip which has specific SKUs for the affordable scale out servers.
Wrapping things up, let’s first look at the POWER8 from a microarchitectural point of view. The midrange POWER8 is able to offer significantly higher performance than the best midrange contemporary Xeon “Haswell-EP” E5s. Even the performance per watt can be quite good, but only in the right conditions (high average CPU load, complex workloads).
IBM’s engineers got their act together in 2014. That might seem like a trivial thing to say, but “Netburst”, “Bulldozer” and “Cell” designs show that building a balanced architecture is not an easy task.
The performance data and analysis is all very interesting, but at the end of the day, what if you are a server buyer? The POWER8 servers are definitely not for everyone. For many people, the superior performance per watt ratio of the Xeon E5-2600 v4 is more attractive. In most virtualized environments, the CPU load is relatively low, and saving lots of power at low loads (at least 100W per socket) will keep the TCO a lot lower.
An – admittedly smaller – part of the market does not care that much about electricity bills, but rather favors performance per dollar. And in that case, the S812LC model that can use cheaper DIMMs to reach the same capacity (32 DIMMs slots instead of 16-24) combined with the relatively cheap POWER8 CPU can make sense. It is important to note that our benchmarks are definitely not the showcases. According to IBM, MariaDB and Postgres have been more optimized for the POWER8 than MySQL. In those cases, IBM claims up to 40% better performance than the Xeon E5-2690 v4.

Those IBM benchmarks show of course the POWER8 in the best light, but we feel we should not dismiss them, just take them with grain of salt. If you read our very first article about OpenPOWER on Linux, you will notice we had trouble getting many workloads to even run. Once we got it working, performance was suboptimal. Now, less than a year later, most of the performance problems have either vanished (MySQL, Spark) or improved a lot (OpenJDK). The OpenPOWER Linux ecosystem gets better at a very fast pace.
IBM asks $ 13141 for the S822LC (“for Big Data”) which includes two 10-core POWER8s, 256 GB DRAM, two 1 TB disks. A similarly configured DELL R730 with Xeon E5-2680 v4 costs around $ 12-13k, a similar HP DL380 costs around $ 15-17k. Though it is admittedly debatable how large the price advantage is as the actual street prices are hard to determine. HP and IBM tend to give bigger discounts, but those discounts get smaller for the most affordable servers.
So although IBM will not convert the masses as the price advantage is not that large, the new POWER8 servers are competitively priced. The bottom line: the IBM POWER8 LC servers can offer you better performance per dollar than a similar x86 server. But it’s not a guarantee; as a server buyer you have to do your research and check whether your application is among the POWER8 optimized ones, and what kind of CPU load profile your application has. The Intel Xeons, by comparison, require less research, and are much more “general purpose”.
Meanwhile the most expensive of the new server models, the S822LC HPC with six quad port NVLINKs and four Tesla P100s, is unique in the HPC market. Given a workload that has real and meaningful bus bandwidth needs, and it is very likely that any Xeon server with 4 GPUs will have a lot of trouble competing with it.
Overall the new POWER8 servers are not a broad full scale attack on Intel’s Xeon. Rather they are a potent attempt to establish some strong beachheads in a number of niche but key markets (GPU accelerated HPC, Big Data).
And looking towards the future, it’s worth considering that the POWER9 will offer a scale out version without the expensive and power hogging memory buffers. With that in the works, it’s clear that IBM and the members of the OpenPOWER foundations are definitely on the right track to grab a larger part of the server market.
Autore: AnandTech