
Author: GAMEmag – Videogames
Dopo aver sconfitto alcuni tra i più forti giocatori di Go, DeepMind si sta adesso specializzando nei videogiochi. Sviluppata da una startup ora controllata da Google, l’intelligenza artificiale ha sconfitto due fra i più quotati giocatori di Starcraft II in una serie di match che si sono svolti lo scorso 19 dicembre. Si parla di Grzegorz “MaNa” Komincz, considerato come uno dei più forti giocatori professionisti di Starcraft II in assoluto e vincitore di due major ufficiali, e di Dario “TLO” Wünsch. Entrambi militano nel Team Liquid.
L’agente IA è stato chiamato AlphaStar e riesce ad essere competitivo, anche contro i giocatori umani più forti, grazie all’aver acquisito conoscenze corrispondenti a 200 anni di gioco con Starcraft II. AlphaStar ha conseguito 10 vittorie in 2 serie separate di 5 partite, prima con TLO e poi con MaNa, perdendo per la prima volta dopo 10 match quando ha affrontato MaNa.

Le partite si sono svolte sulla mappa Catalyst su una versione leggermente datata di Starcraft II, usata come punto di riferimento per le ricerche nel campo dell’intelligenza artificiale. DeepMind, infatti, è stato da tempo adattato a Starcraft II, considerando come un valido campo di prova per via della sua complessità e profondità strategica. Mentre TLO, prima dei match, aveva dichiarato di sentirsi sicuro di battere l’agente AI, AlphaStar è riuscito a vincere tutti e cinque le partite contro di lui, impiegando ogni volta strategie diverse.
AlphaStar però aveva dei vantaggi nelle sue partite contro TLO. Innanzitutto, si usavano i Protoss, che non è la fazione preferita da TLO. Inoltre, e ancora più importante, l’intelligenza artificiale visualizza sull’intera mappa, che vede nella sua totalità senza ‘fog of war’. Questo vuol dire che può seguire tutti i movimenti dell’avversario fin dall’iniio della partita e soprattutto non deve perdere tempo a fare zoom in e zoom out sulla mappa.
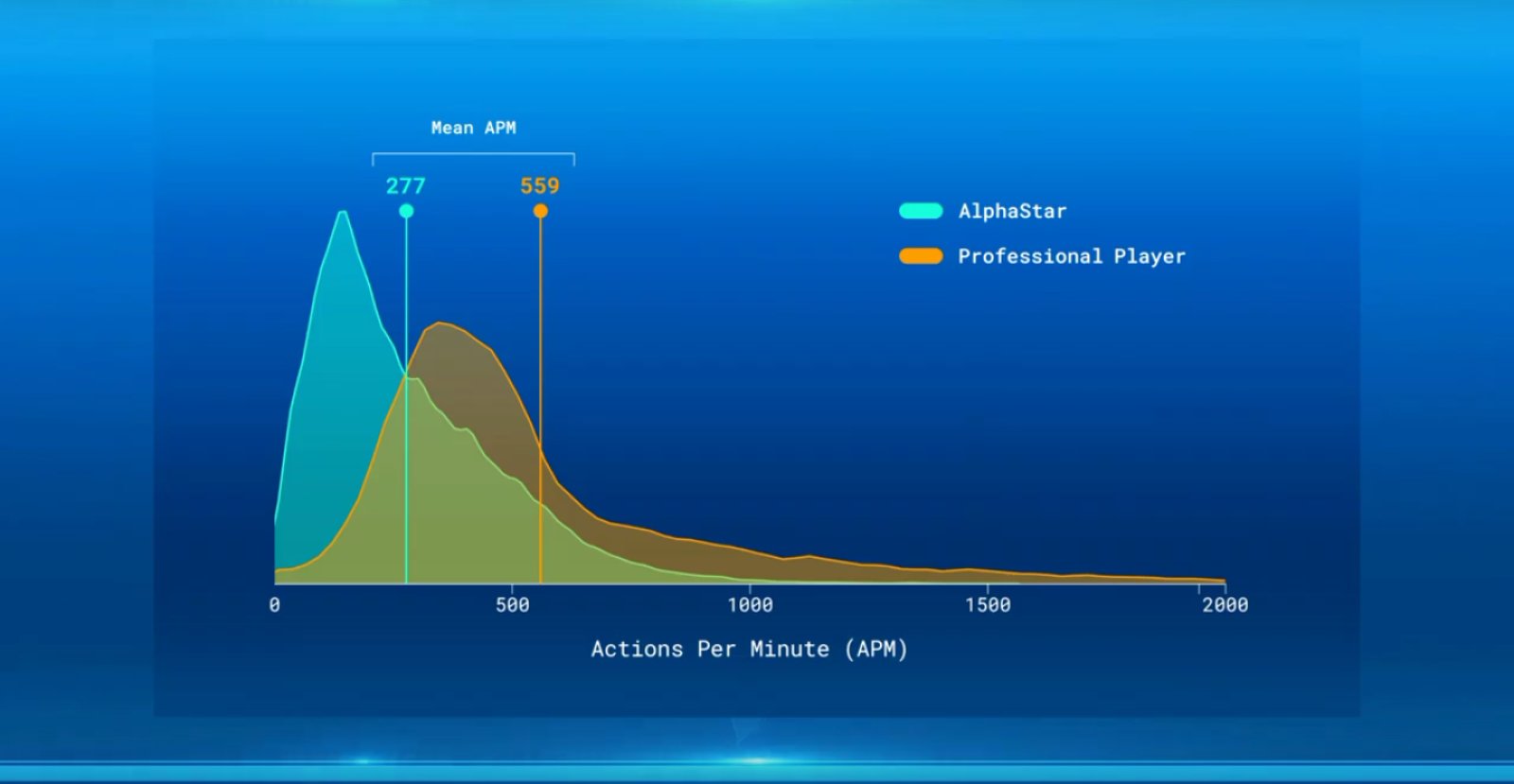
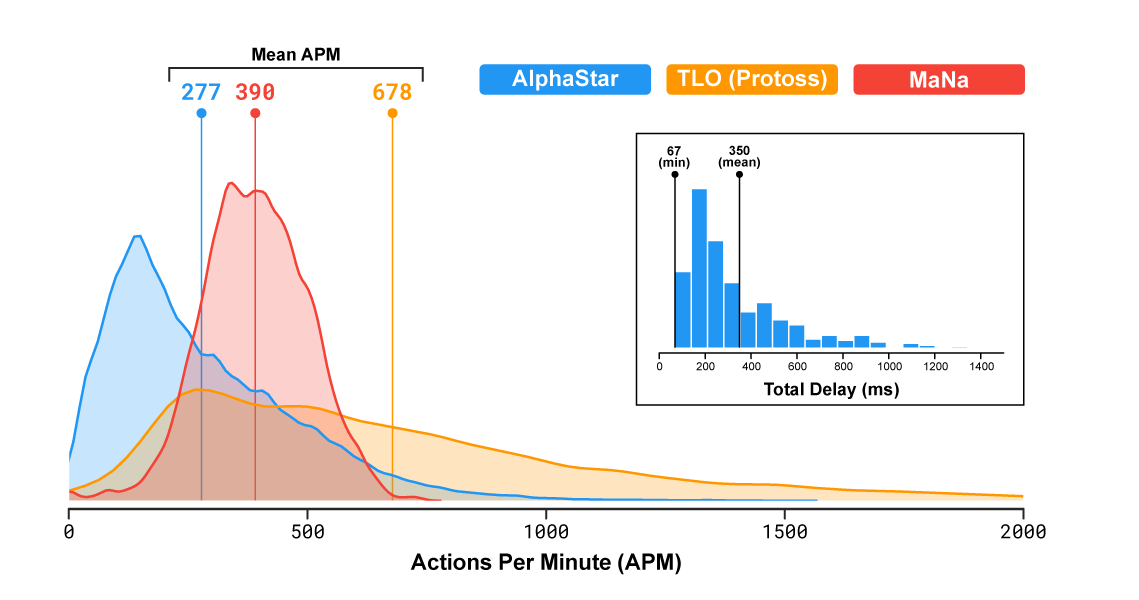
Se teoricamente AlphaStar non ha un limite fisico nel numero di azioni che può eseguire al minuto, effettivamente ha eseguito meno azioni al minuto dei suoi avversari umani e significativamente meno del normale giocatore professionista. L’intelligenza artificiale ha avuto un tempo di reazione di circa 350 millisecondi, superiore a quello della maggior parte dei professionisti. L’IA tende a prendersi il tempo necessario in modo da prendere decisioni più intelligenti ed efficienti che le possano permettere di acquisire vantaggi significativi.
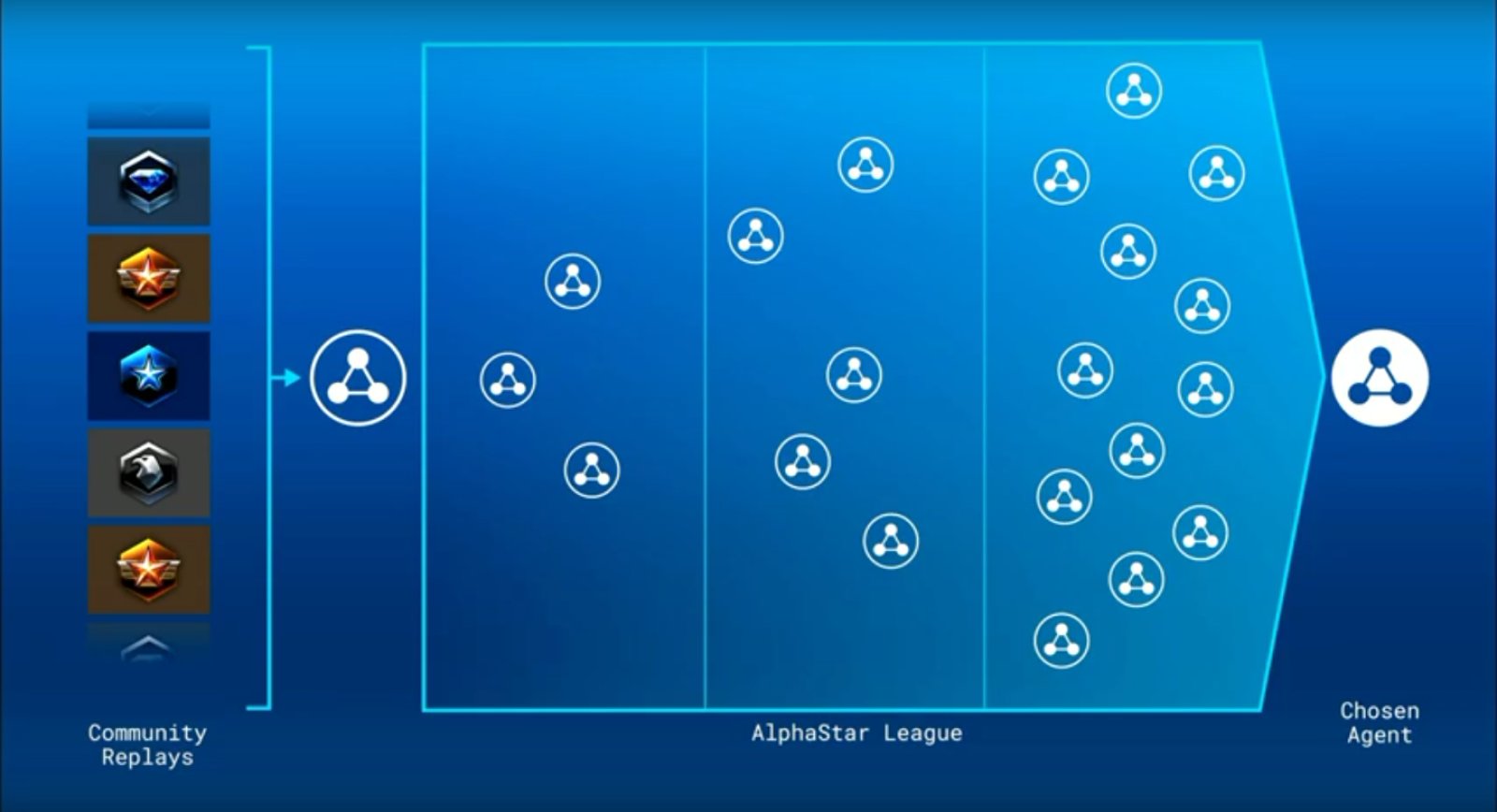
L’esperienza di AlphaStar nel gioco deriva principalmente da un programma di formazione approfondito che DeepMind chiama AlphaStar League. DeepMind ha analizzato una moltitudine di replay di partite fra giocatori umani e ha iniziato ad allenare una rete neurale basata su quei dati. L’agente creato in questo modo è stato duplicato e due versioni sono state fatte affrontare l’una contro l’alta. Successivamente, le varie versioni sono state spinte a padroneggiare aspetti differenti del gioco.
AlphaStar League ha avuto una durata di una settimana, durante la quale le partite che venivano introdotte producevano nuove informazioni contribuendo a perfezionare la strategia dell’intelligenza artificiale. Nel corso di questa settimana, AlphaStar ha conseguito un’esperienza paragonabile all’esperienza che avrebbe potuto ottenere giocando a Starcraft II per 200 anni. Alla fine della sessione AlphaStar ha determinato quali fossero i cinque tipi di strategia più difficilmente contrastabili dai giocatori umani e li ha adottati nei match contro TLO e MaNa. Dopo che sono stati determinati gli avversari da affrontare, inoltre, AlphaStar è stato sottoposto a un’ulteriore settimana di apprendimento, durante la quale ha analizzato alcuni match di TLO con i Protoss.
Durante i match, come sottolineano i commentatori, l’intelligenza artificiale ha assunto un comportamento molto simile a quello di essere umano, abbandonando alcune delle sue azioni più imprevedibili e inaspettate, e dimostrando di avere messo a punto uno stile basato su un processo decisionale più articolato grazie all’aver visionato TLO.
Ha dunque vinto i cinque match contro TLO e i cinque contro MaNa, nonostante entrambi si siano impegnati pienamente per ottenere la vittoria. Dopo queste dieci partite, però, ne è stata trasmessa un’undicesima in live streaming, dove l’IA non ha più goduto del vantaggio di visualizzare l’intera mappa di gioco. In questo modo, ha dovuto concentrare delle risorse di attenzione sulle decisioni sulla parte della mappa da visionare. Questa partita è stata dunque vinta da MaNa.
DeepMind spiega la sconfitta con il fatto che AlphaStar non ha avuto modo di allenarsi contro un essere umano nella modalità di scontro che non prevede la visione della mappa completa. Può, infatti, velocizzare le operazioni con parte della mappa nascosta se sufficientemente allenato.
Con la restrizione al punto di vista di AlphaStar, MaNa è stato in grado di sfruttare alcune delle carenze dell’IA, infliggendo ad AlphaStar la sua prima sconfitta contro i giocatori professionisti.
Resta il fatto che AlphaStar è in grado di apprendere in maniera incredibilmente veloce: seguendo le sue azioni in match, i giocatori professionisti possono così apprendere delle strategie nuove attingendo all’enorme esperienza acquisita dall’intelligenza artificiale. Il set completo di replay di tutte le partite di AlphaStar contro TLO e MaNa è disponibile sul sito di DeepMind.