
Author: IlSoftware
/https://www.ilsoftware.it/app/uploads/2023/12/VRAM-estimator-LLM-IA.jpg)
I Large Language Models (LLM) sono modelli di linguaggio avanzati che sfruttano reti neurali profonde per apprendere e comprendere il linguaggio naturale. Quando si parla di eseguire LLM in locale, significa ospitare e far funzionare il modello direttamente su una propria macchina o su un server cloud sotto il proprio esclusivo controllo. In questo modo, tutte le elaborazioni avvengono affidandosi a risorse nella propria disponibilità, senza fare affidamento a terzi.
Intelligenza artificiale e modelli generativi sono al servizio delle decisioni aziendali: è infatti possibile utilizzarli per fare inferenza a partire dall’enorme mole di dati che ciascuna azienda possiede.
Come stabilire quanta VRAM è necessaria per eseguire e gestire ciascun modello generativo
L’uso di GPU ad alte prestazioni è essenziale per accelerare il calcolo parallelo richiesto durante le fasi di addestramento e inferenza dei LLM. Interessante, è questo servizio che aiuta a stimare il quantitativo di memoria VRAM necessario per sostenere adeguatamente il funzionamento di uno tra i più popolari e apprezzati modelli.
VRAM Estimator è uno strumento open source il cui sorgente è pubblicato sul corrispondente repository GitHub. Calcola l’impegno in termini di memoria video (VRAM) durante l’addestramento e l’ottimizzazione dei modelli linguistici basati su transformer.
I CUDA Kernel sono componenti software specifici della GPU che eseguono operazioni in parallelo. Al primo utilizzo della GPU, i kernel CUDA utilizzeranno tra 300 e 2000 MB, valore che può variare in base alla tipologia di GPU, driver e versioni di PyTorch utilizzati. PyTorch è un framework open source di machine learning e deep learning sviluppato principalmente da Facebook. Fornisce un set di strumenti e librerie che semplificano la creazione e l’addestramento di modelli di machine learning, in particolare su reti neurali profonde. PyTorch è ampiamente utilizzato in ambito accademico e industriale ed è noto per la sua flessibilità e facilità d’uso.
Nell’interfaccia di VRAM Estimator, si trovano gli strumenti per effettuare valutazioni sia in termini di addestramento che inferenza.
I termini utilizzati da VRAM Estimator
Nella pagina di riferimento del tool VRAM Estimator si trovano i vari aspetti che incidono in maniera preponderante sull’occupazione della memoria VRAM e quindi sui requisiti hardware per gestire specifici LLM.
Mixed Precision Training, ad esempio, è una tecnica di addestramento che utilizza precisione mista, cioè la rappresentazione sia a 16 bit (float16) che a 32 bit (float32) per ottimizzare il tempo di calcolo e ridurre la dimensione delle attivazioni. Quest’ultima corrisponde alle dimensioni dei tensori che rappresentano gli output intermedi di uno strato o di un insieme di strati all’interno della rete neurale durante la fase di elaborazione dei dati.
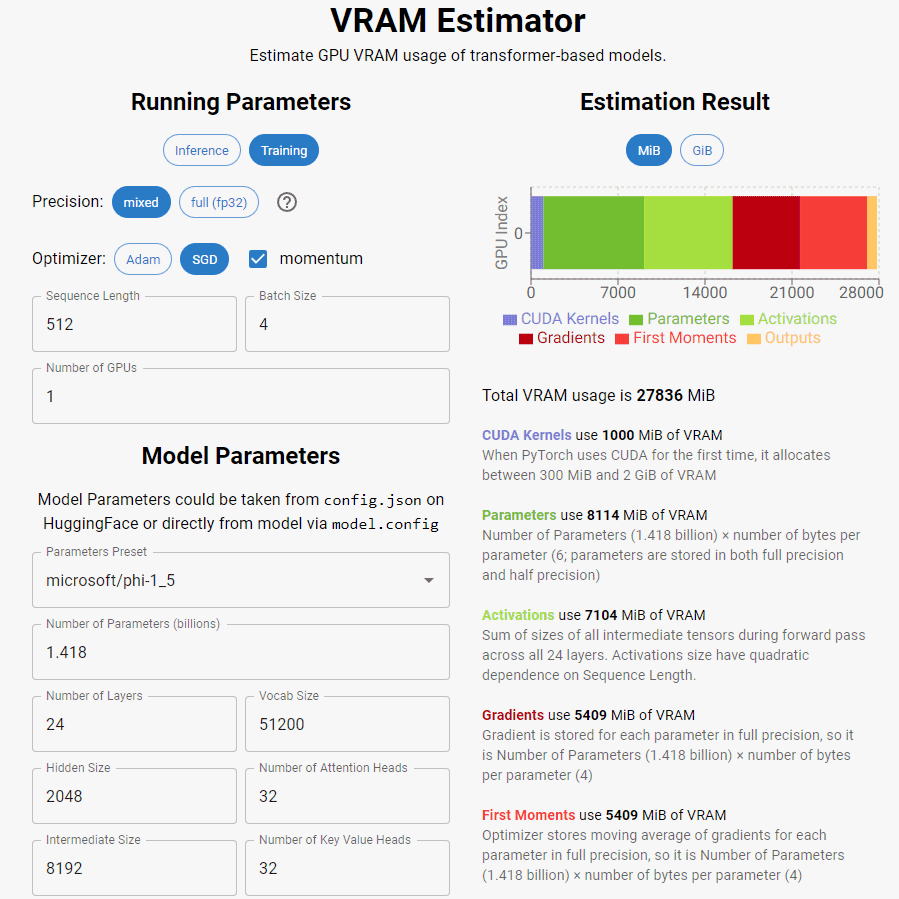
Oltre alla precisione dei dati utilizzati durante i calcoli, tra i concetti chiave ci sono l’optimizer o ottimizzatore. È un componente fondamentale durante l’addestramento perché determina come vengono aggiornati i pesi del modello. L’obiettivo dell’ottimizzatore è minimizzare la funzione di perdita del modello, regolando i pesi in modo che il modello migliori le sue prestazioni.
La lunghezza della sequenza (Sequence Length) si riferisce al numero di passaggi temporali in una sequenza di dati. In contesti come il linguaggio naturale, rappresenta la lunghezza delle sequenze di parole o campioni considerati.
Un parametro come batch size rappresenta il numero di esempi di addestramento utilizzati in una singola iterazione e permette di parallelizzare i calcoli sulla GPU in modo più efficace. Ovviamente, una batch size di ampie dimensioni può accelerare il processo di addestramento, ma può anche richiedere più memoria.
Infine, Number of GPUs, esprime il numero di unità di elaborazione grafica (GPU) utilizzate durante l’addestramento del modello. Alcuni modelli possono essere addestrati in parallelo su più GPU.
Intervenendo sia sui parametri legati all’esecuzione del modello, sia su quelli specifici del singolo LLM scelto usando il menu a tendina Parameters Preset, è possibile ottenere una stima della memoria VRAM necessaria.
Credit immagine in apertura: iStock.com – Digital43